GPU code
WOLFGPU est une version GPU du code WOLF2D. Il est écrit en Python et OpenGL 4.6.
Architecture
Le code GPU peut s’appuyer sur deux structures d’entrée différentes:
une modélisation WOLF2D compatible avec le Fortran, ce qui permet de réutiliser des modélisations existantes
une structure plus simple, appelée “SimpleSimulation”, qui permet de le mettre en place facilement par l’API
Une instance GLSimulation est créée à partir de l’une de ces structures. Cette instance est ensuite utilisée par le SimulationRunner pour piloter la simulation.
Les résultats sont affichés en temps réel dans une fenêtre OpenGL.
Le reporting des résultats est géré par le ResultStore qui assure l’écriture et la relecture des inconnues de calcul mais également des métadonnées associées (pas de temps, temps total simulé…).
Note
Les résultats sont actuellement stockés sous la forme de matrices Numpy au format Compressed Sparse Row.
Ceci peut cependant évoluer sans préavis. La rétro-compatibilité sera assurée via le ResultStore uniquement.
Une autre classe Python gère l’affichage des résultats dans la fenêtre graphique du viewer. Cette classe peut potentiellement mettre les résultats en cache afin d’accélérer l’analyse sur plusieurs pas de temps.

Synthèse des fonctionnalités (GPU)
Schéma de discrétisation en espace : volumes finis
Méthode de reconstruction des inconnues : constante par maille
Lois de frottement : Manning/Strickler
Discrétisation spatiale : grillage cartésien, taille de maille unique
Discrétisation temporelle : RK21, RK22
Précision de calcul : virgule flottante simple précision (32 bits)
Conditions aux limites : débits spécifiques, hauteurs d’eau, altitude de surface libre, Froude
Zones d’infiltration/exfiltration : nombre illimité, interpolation linéaire ou constant par palier
Mise à jour de la topographie en cours de calcul : oui
Note
Le pas de temps est calculé automatiquement par le code en fonction de la vitesse de propagation des ondes de gravité et de la vitesse de l’écoulement. Il est possible de spécifier un nombre de Courant cible pour ajuster la stabilité du calcul.
Ordre de grandeur :
vitesse de calcul : 500 millions de mailles / seconde en RK22 sur un processeur Intel i9 et carte RTX3090
pas de temps : de 0.01 à 0.1 seconde pour des écoulements de type crue sur maillage de 1 mètre
Benchmarking
Une option de benchmarking est disponible pour tester les performances du code sur différentes cartes graphiques.
Le benchmarking consiste à exécuter le code sur des grilles carrées de tailles:
512 x 512
1024 x 01024
2048 x 2048
4096 x 4096
5120 x 5120
6144 x 6144
7168 x 7168
8192 x 8192
Le problème est un bac aux parois impermaéables avec une hauteur d’eau initiale nulle, sauf sur une colonne centrale.
Les résultats sont enregistrés dans un fichier CSV.
Note
Pour information, la machine de test la plus puissante est équipée du matériel suivant:
processeur Intel i9-12900KF (16 coeurs)
carte mère Asus Prime Z690-P
128 Go DDR5 4800
Disque SSD Samsung 980 Pro 1To + HDD WD 4To
Windows 11 Pro 64 bits
Cinq cartes graphiques ont été testées sus Windows10/11:
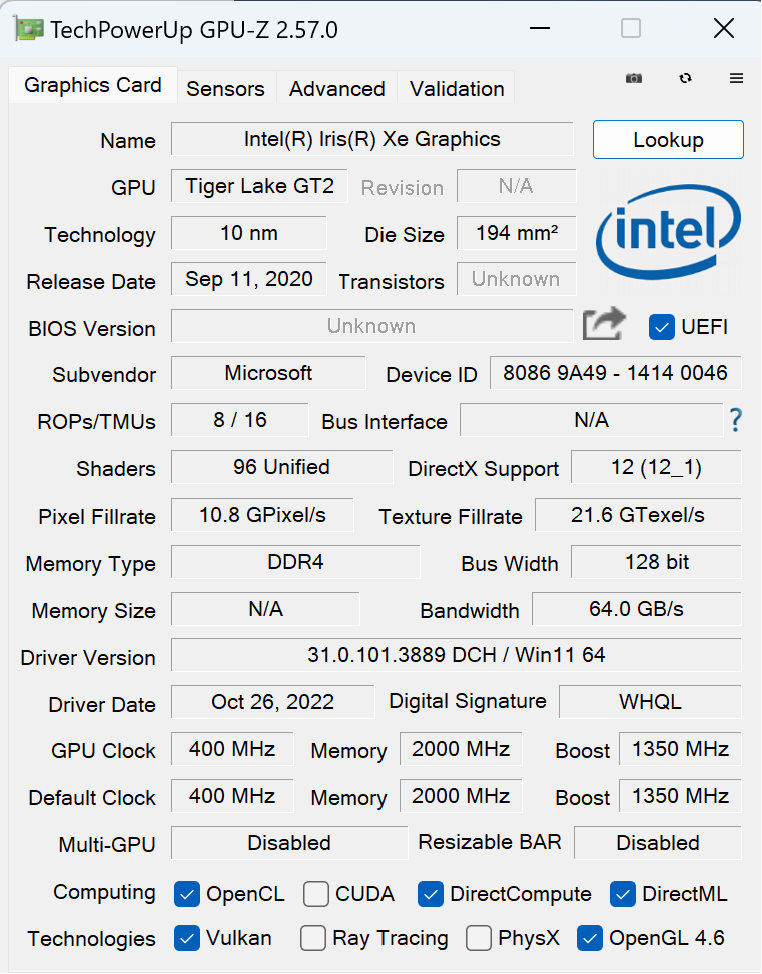
Nvidia RTX3090 (PC ci-dessus)
Nvidia RTX3060
Nvidia RTX4060
Nvidia GTX1080Ti
Intel Iris Xe (Portable Surface Pro 8)
Les caractéristiques des cartes graphiques sont les suivantes:
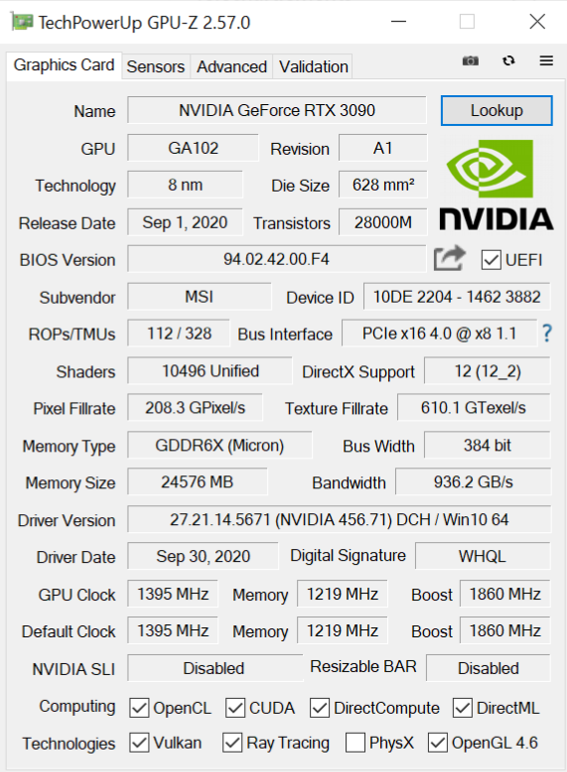
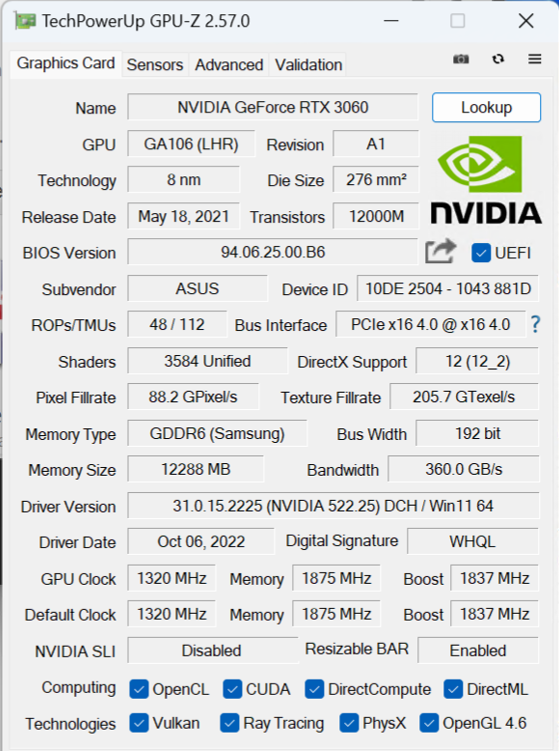
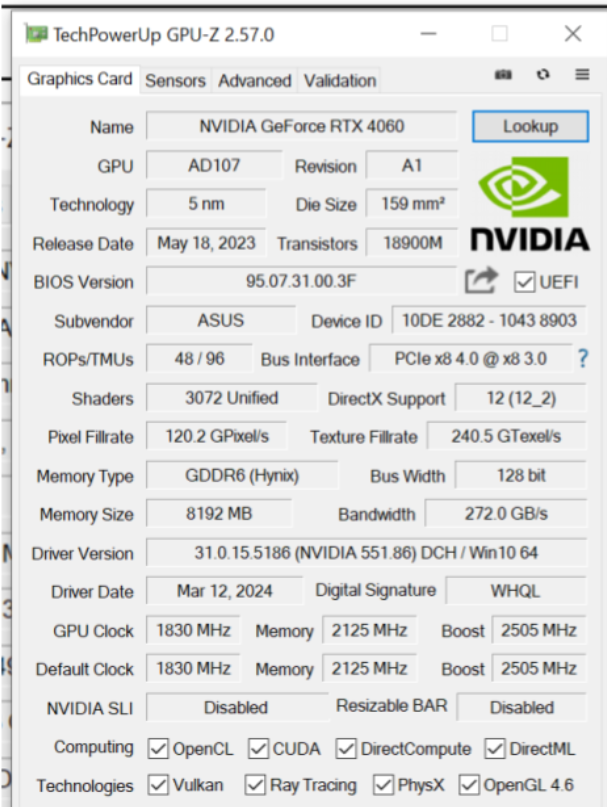
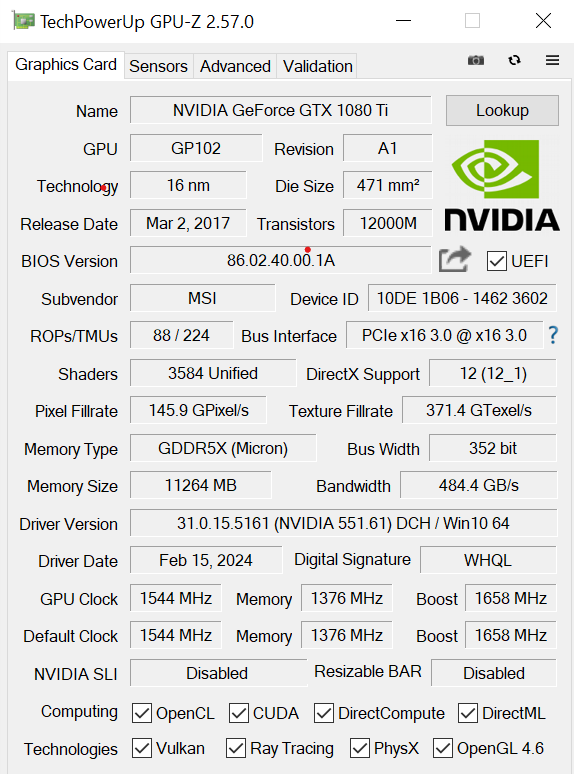
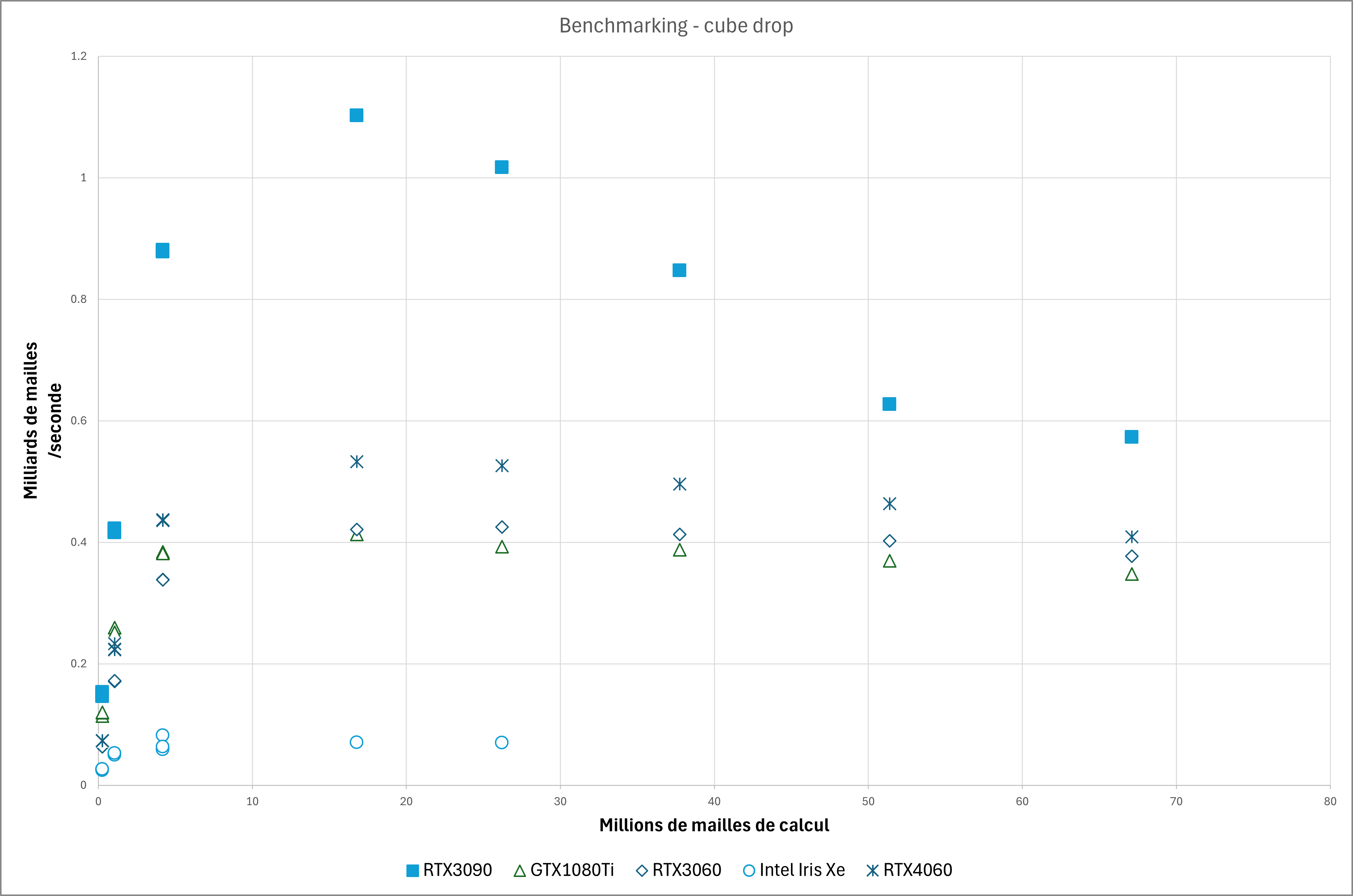
Le graphique suivant montre les performances des différentes cartes sur base du nombre de noeuds calculés par seconde en fonction de la taille du problème.
Note
Il est possible d’obtenir un code plus rapide en exploitant certains paramètres liés notamment à la gestion de l’assèchement (-dry-up-loops) ou au tiling (-tile-size ; -no-tiles-packing). Il est toutefois du ressort du modélisateur de faire ces choix en connaissance de cause.
Des travaux sont encore en cours afin de poursuivre l’optimisation du code (utilisation mémoire et vitesse pure).
Note
Les caractéristiques des cartes graphiques NVIDIA sont accessibles en ligne.
Les caractéristiques des cartes graphiques AMD sont accessibles en ligne.
Le choix de la carte est du ressort de l’utilisateur en fonction de ses besoins et de son budget.
Pour le développement du code, l’option de l’OpenGL 4.6 est un choix délibéré pour garantir une compatibilité maximale et ne pas dépendre d’un constructeur spécifique.
Exécution de l’application
L’application peut être exécutée en utilisant la commande suivante :
wolfgpu
Il est également possible de lancer le code via un appel python:
python -m wolfgpu.cli
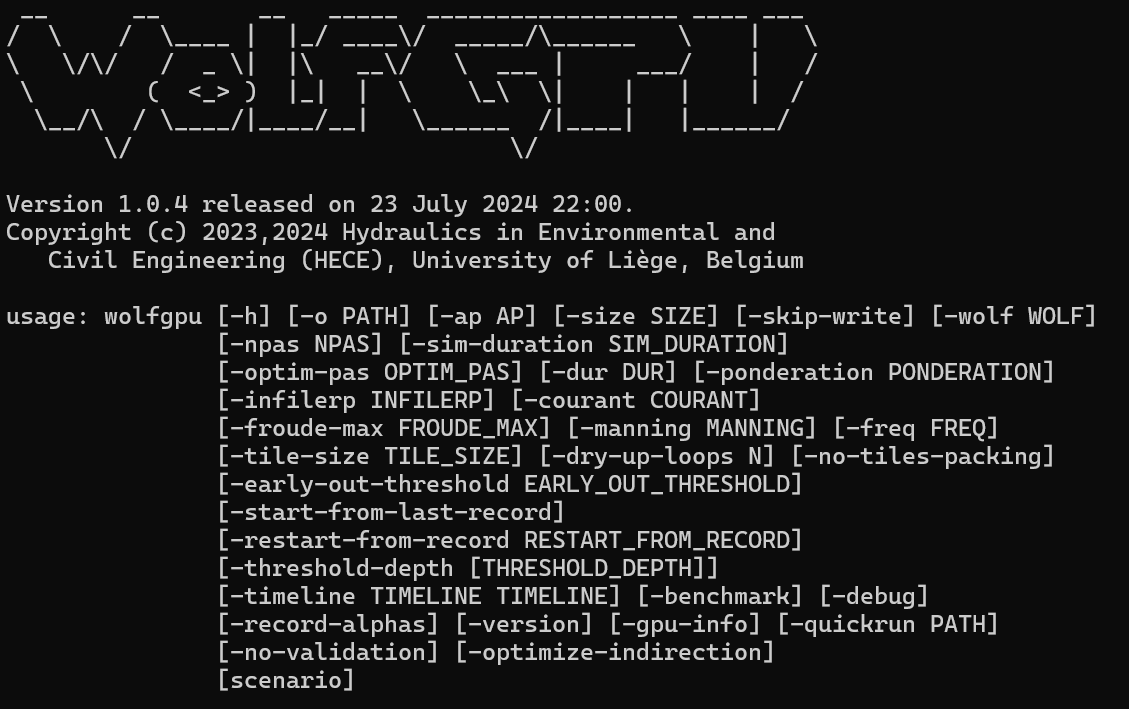
Il est possible de spécifier des options pour l’application. Pour obtenir la liste des options disponibles, il est possible d’utiliser la commande suivante :
wolfgpu --help
Note
Ces commandes peuvent évoluer au fur et à mesure des versions.
Il est donc utile de vérifier les options disponibles pour chaque version.
Exemple pour la version 1.0.4 :

Mise à jour de la topo en cours de calcul
Il est possible de mettre à jour la topographie en cours de calcul. Pour cela, il faut mettre à jour le fichier de topographie que le code scanne régulièrement en cours de calcul.
Les informations sur le nom du fichier à adapter sont dans le help de l’application. Ces informations pourront évoluer en fonction des versions du code de calcul.

Scénario préconfigurés
Plusieurs scénarios sont disponibles pour tester les performances du code.
Il s’agit de scénarios relativement simples qui permettent de vérifier le bon fonctionnement du code.
Exécution du scenario “cube drop” disponible avec le code
Note
Ceci est peut-être anodin pour certains mais il est bon de remarquer que le code reste totalement symétrique sur toute la durée de l’exécution.
Premier modèle
Un modèle simple sur base d’un Jupyter Notebook est disponible.
Ce fichier illustre les étapes pour préparer les données, lancer le code de calcul et accéder aux résultats par 2 moyens différents.
Données d’un modèle simple
La structure d’un pur modèle GPU est nettement plus simple que celle d’un modèle 2D CPU multiblocks.
En effet, un modèle GPU SimpleSimulation contient :
une matrice de topo_bathymétrie : bathymetry.npy (en numpy.float32)
une matrice de coefficients de Manning : manning.npy (en numpy.float32)
une matrice de domaine de calcul: NAP.npy (en numpy.uint8)
une matrice d’infiltration/exfiltration : infiltration_zones.npy (en numpy.int32) (optionnelle)
3 matrices de conditions initiales : h.npy, qx.npy, qy.npy (les 3 en numpy.float32)
une matrice d’altitude de toit : bridge_roof.npy (en numpy.float32) (optionnelle)
un fichier de configuration : parameters.json (texte ASCII)
Le format des fichiers est donc du pur Numpy (ce qui facilite grandement la lecture et l’écriture depuis un script/Notebook voire un outil externe). Cependant, ce type de fichier ne contient pas de positionnement spatial. Ce dernier est contenu dans le fichier de paramètres via les clés : base_coord_ll_x, base_coord_ll_y, dx, dy. ll pour lower-left. D’autres clés (exemple : nx, ny) sont redondantes avec les dimensions des matrices mais permettent des vérifications internes.
Note
Il est particulièrement recommandés de bien vérifier le typage des matrices lors de leur création via script/Notebook. Des vérifications internes sont effectuées mais il s’agit d’une erreur courante qu’il est possible de commettre.
Le fichier de paramètres est au standard JSON et peut être modifié à volonté. Il contient les conditions aux limites et les hydrogrammes.
Exécution de l’application sur une machine équipée de plusieurs cartes graphiques
A l’heure actuelle, l’application wolfgpu n’exploite qu’une seule carte graphique. Seules les cartes NVidia (GTX ou supérieure) et une carte intégrée Intel ont été testées.
Warning
Toute carte avec des capacités OpenGL 4.6 devrait pouvoir exécuter le code.
Toutefois, la compilation du code est effectuée sur la carte et par le driver du constructeur. Il n’est donc pas possible de garantir le bon fonctionnement de l’application sur toutes les cartes graphiques du marché.
De même, l’implémentation des opérateurs mathématiques dépend également du constructeur de la carte graphique. Aucune garantie de reproductibilité totale, c’est-à-dire une stricte comparaison binaire des résultats pour plusieurs exécutions succesives ou sur des machines différentes, n’est donc possible sans test approfondi du matériel.
Si la machine est équipée de plusieurs cartes graphiques, il est normalement possible de spécifier la carte à utiliser en utilisant le panneau de contrôle (par exemple “NVidia Control Panel”) et en particularisant la carte à utiliser pour le rendu OpenGL.
Cette option est normalement disponible pour un exécutable en particulier.